
Trams, Telemetry, Agile & Architecture
NFVi telemetry enables multiple use cases. Having both strategic architecture and agile views of these will help guide successful delivery of an open source based telemetry solution.

Murphy’s law hit again recently on a Melbourne Thursday. Earlier in the day there had been a tram strike. I had a meeting to get to and tram services were only just resuming. My assumption, on leaving the office, was that I would catch a tram to get to my meeting in about 15 minutes.
I was now at one end of the CBD needing to get to a location in middle of town in around 17 minutes. Choices included: wait for tram, catch a taxi or walk fast / run to get to my meeting on time ?
With no trams in sight, I jumped into a taxi, asking for express route straight through town. The driver informed me that the direct route was closed and the detour took much longer and was traffic jammed. So out of taxi and onto "plan C", a fast hike to next major tram intersection. On way I send a message that I might be a bit delayed due to tram strike.
At the intersection I can see trams going in various directions. I ask a service officer, providing assistance to disgruntled passengers, if he knows when the next tram will be heading up Collins St. His response, “… I do not know, but it should be within next 15 to 20 minutes …”. So wait or hike. Best to hike, as I might be a little late, but it allows me to act now and keeps me heading in the right direction, the alternative puts me at mercy of chance and luck.
On the way I thought about how this situation was analogous to many “Enterprise Architecture vs Agile” debates / discussions, the most recent being on the approach to telemetry within Network Function Virtualization infrastructure (NFVi).
So to NFVi telemetry and architecture.
Telemetry is the underpinning of many machine learning and closed loop automation use cases which aim to significantly reduce cost of operating large telco networks. The simple view is that you feed the telemetry into a "big data" machine learning algorithm which then makes intelligent automatic remediation decisions, triggering actions such as: scaling up/down resources, moving workloads to alternate machines and taking healing actions by using alternate network paths. This focus on single use case, feeds well into agile delivery pipeline. It uses well understood technical components and the various fault use cases can be knocked off by feeding backlog and coding the actions.
A “higher level” architecture view illustrates that there are a broader set of concerns to be satisfied. Further analysis shows that the data needs for this core set of eight use case use much of the same set of underlying data (massaged and accumulated is various ways).
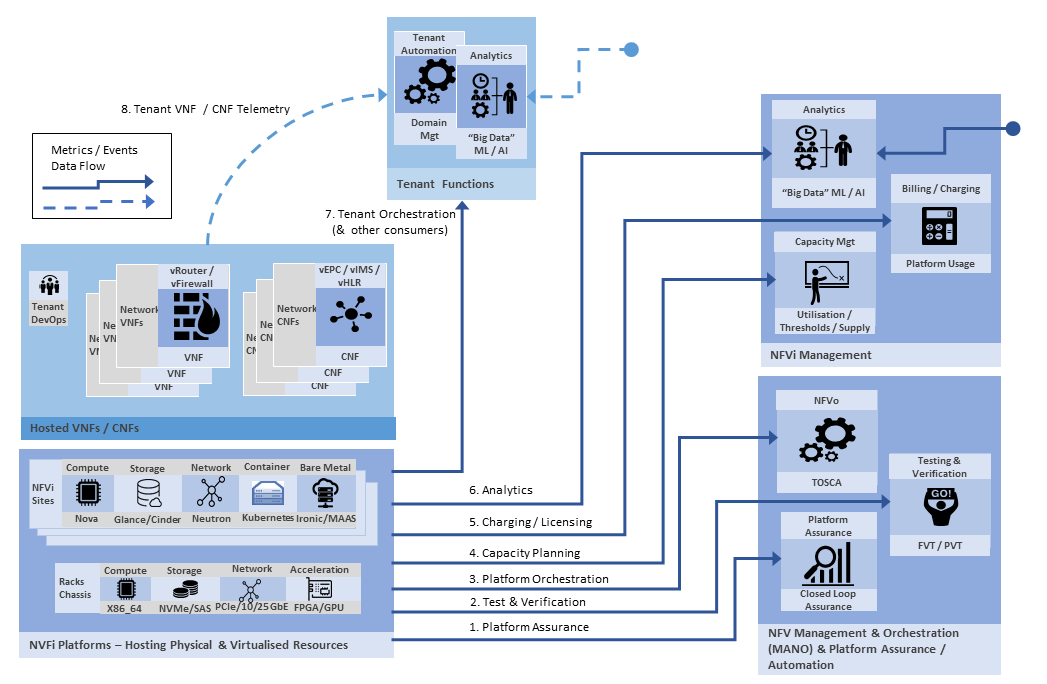
- Platform Assurance – the immediate use case for “closed loop assurance”. Provides visibility of operational systems and uses metric and event data as feed to trigger remediation actions
- Test & Verification – being able to meet non-functional requirements for performance is pretty much the life blood of NFV and performance and bench marking suites are typically fed from same metrics as assurance platforms
- Platform Orchestration (NFVo) – needs visibility of VNF/CNF stop / start and performance data to be able to make scaling and deployment decisions
- Capacity Management – requires rolled up summary of resource utilisation which is generated from underlying metrics collection
- Charging / Licensing – uses consumption and utilisation metrics for charging and VNF/CNF stop / start events for license audits
- Analytics – metric and events feed network analytics, along with other sources of enrichment data
- Tenant Orchestration (& other consumers) – in multi-tenanted NFVi scenarios, it is desirable for tenants to get access a sub-set of underlying platform telemetry data
- Tenant VNF / CNF Telemetry – in addition to platform level telemetry VNF/CNF functions can also generate their own application specific telemetry
Most discussions on NFVi telemetry focus on a single one or two of these use cases (typically #1 plus #3 or #4) in isolation. What happens in practice is that you have multiple teams putting their own instrumentation into infrastructure, blocked backlogs and work done to satisfy one use case needs to be redone for the other.
The obvious solution is to do a quick strategic architecture brushstroke … a central collection point into which others can subscribe. This can be built on top of: rsyslog, Fluentd, collectd and Apache Kafka technologies providing ease of consumption and integration with real time support. The Central Collector provides data subscription point to all of the other functional uses cases, abstracted across OpenStack and Kubernetes based platforms and it meets the non-functional needs! Problem solved ;-) .
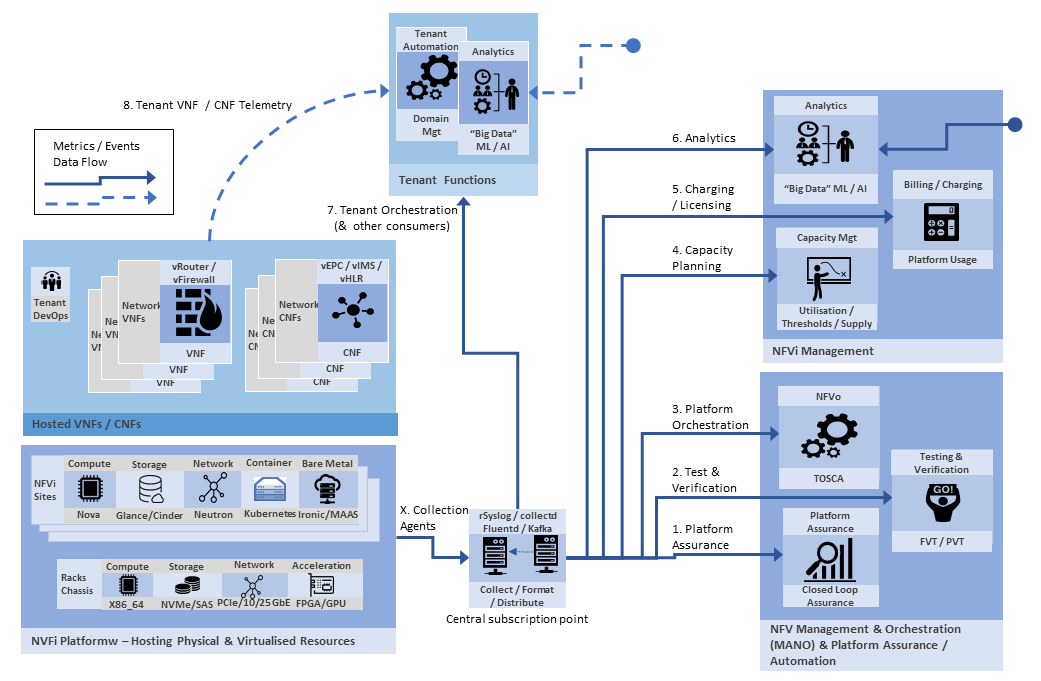
The technical reality is a little different. OpenStack telemetry is currently (Pike, Queens, Rocky releases) in state of substantial flux and shifting from Ceilometer to collectd based collection. Riemann is used as feedback interface for many Orchestration solutions, including Cloudify. Prometheus time series database is used for collection of metrics within Kubernetes based platform while OpenStack has Gnocchi as its default time series database. Prometheus uses pull model for collection, while collectd & Fluentd are “pushers”. Both collectd and Fluentd are highly configurable both in terms of what data is collected and where it is written to. While Kafka has a great consumption model, many of the available (via GitHub) code sets use direct integration from the collection agent (collectd / fluentd) to the destination target (Prometheus, Cloudify, Riemann, ZenOSS by way of examples) and so adding Kafka consumer requires writing additional code. Yes the details are messy!
So to the tram question: Wait for the world to align to simple strategic view, start coding a Kafka generic distribution solution or focus on particular functional use case without concern for broader needs ?
This is where Enterprise Architecture and Agile approaches work best if they work together. The value in EA view is that it provides a quick basis for review and validation of first and subsequent steps towards strategic target, while Agile view should define what is immediately actionable.
In context of NFVi telemetry the right decision is totally dependent on priority of particular use cases. Organisation are at varying levels of maturity and have different priorities. In case of an Agile delivery pipeline entering a “wait” state should be avoided. Again in context of NFVi telemetry, there is usually more than sufficient issues or needs to ensure that delivery momentum can be maintained, even if there will need to be some adjustments on the way.
So did hiking get me on to meeting on time ?
No - I was five minutes late, but by signalling ahead that I would be late I managed to get there five minutes before the other party. Calling ahead is an example of the virtue of transparency, a key agile tenant.
Would I have got there on time by tram ?
Who knows I might have but by the same token I could have been 30 minutes late and I did get a chance to think about NFVi telemetry while walking. If I was waiting, I would likely haven been occupied with looking at my phone for time and getting agitated about when the next tram was arriving.
Glossary:
CNF - Cloud (Native) Network Function (a VNF built as a Container app for deployment in Kubernetes)
NFVi - Network Function Virtualisation infrastructure
NFVo - Network Function Virtualisation Orchestration
Telemetry Data - in this context covers both metric (performance) and event (syslog / snmp) data generated by NFVi platform and VNFs / CNFs running within this.
VNF - Virtualised Network Function
References:
ETSI Network Function Virtualisation (NFV) - Architectural Framework
Some Telemetry Technical Stuff:
collectd - Open Source metrics and log collection framework (for OpenStack)
Fluentd - Another Open Source metrics and log collection framework (for Kubernetes)
Gnocchi - Open Source time series database that was developed as part of Open Stack telemetry
Kafka - Open Source Streaming Platform
Kubernetes - Open Source Container Deployment and Orchestration Solution
OpenStack - Open Source Multi-Tenant Infrastructure as a Service
Prometheus - Open Source Time Series and Monitoring system
NOTES 1: Authors "first step" on Open Source telemetry was to get some bugs in collectd resolved to allow deployment on Ubuntu 18.04 & 19.04
NOTES 2: The instrumented bumblebee (picture) from Wikipedia Telemetry page (do bee's do architecture and are they agile...?)
NOTE 3: Look at what a bee can do and think about its size and energy efficiency relative to a "big data ML system", we have a long way to go ;-)
NOTES 4: Tram drivers strike for better pay..