
Ubuntu Linux Crashed ...
Understanding the Linux boot process, layers and typical scenarios is helpful in recovery from crash.

Fact - if you run a computer then it will crash.
So be prepared and some notes on what to do.
Status: August 2023 - Server crashed ! Server restored :-) . Just writing up a few useful things / scripts for next time.
Introduction
This information is based on a Ubuntu Linux server crash.
A server crash is likely to be the result of:
- Hardware failure - most common being disk failure
- Operating systems software install failure - either installed new OS level software that caused failure or operating systems upgrade resulted in failure
It frequently happens that failure can result in compounding problems. On Linux the most frequent failure are seen for:
- UEFI Boot Failure - where you get dumped into the EFI Shell
- GRUB Failure - where you get dumped into GRUB shell
- Linux Kernel Load Failure - which is likely to result in boot loop
- Linux Init Process failure - where kernel loaded but there is failure in the init process which starts up various OS processes
- User Process failure - systems boots up ok but user cannot login or experiences some other problem which stops them from using the machine
These note are broken into these different areas to help with diagnosis and fix of problem. They are collected based on problems faced only and are not comprehensive, just what was found and fixed (or not fixed). The focus is on diagnosis and fixing not on avoidance.
NOTE: All of these example are on based on dedicated single boot Ubuntu server (i.e. no multi-boot of Windows and other operating systems).
UEFI Boot Failure
If you get UEFI failure then it could be due to not finding an EFI partition (i.e. no bootable disk, cd, usb) or it found an EFI partition, but could not find OS disk to pass next boot stage step too (such as GRUB).
If you are in UEFI shell you should see something like this:
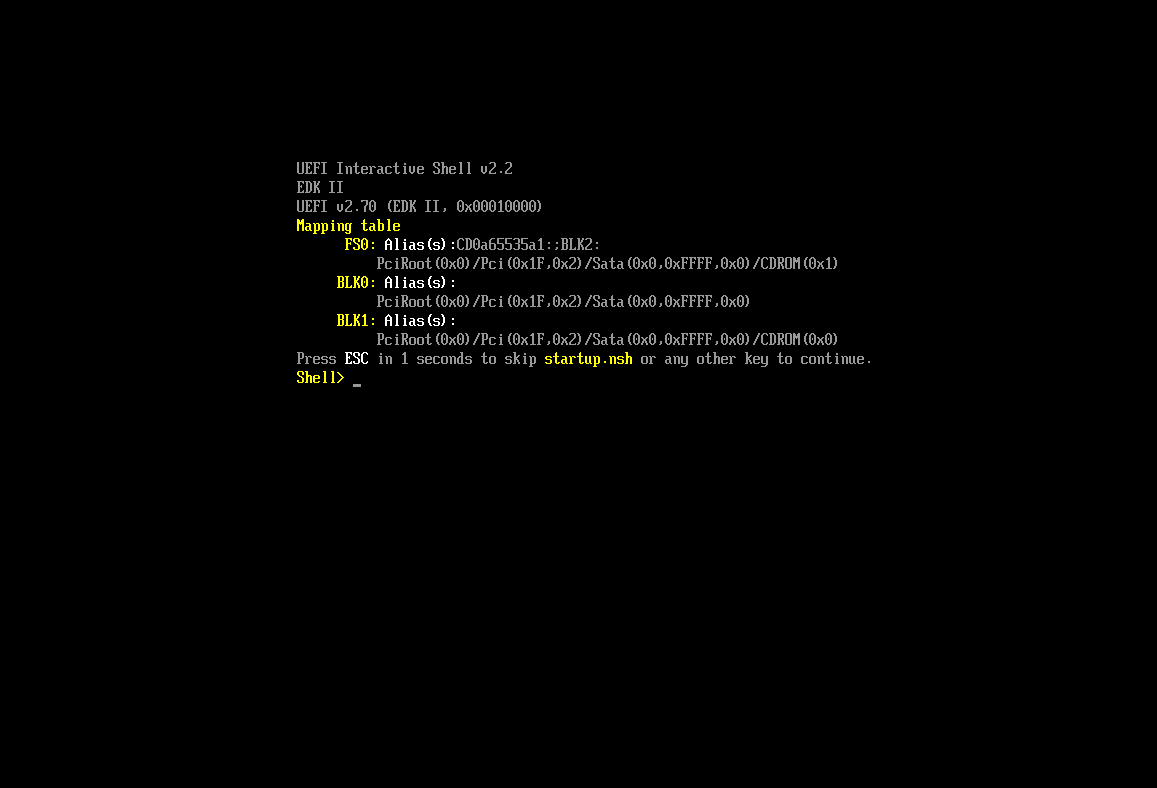
If you are running your machines via hypervisor (KVM / QEMU for Ubuntu) then if you get this then it it likely due to:
- Using virtual storage driver that is not supported by operating system so no disk is found, so change the disk driver type (SATA is lowest common denominator for UEFI machine)
- The UEFI partition does not have required boot drivers, so do install/re-install of UEFI boot drivers
Other possibility is that you have not selected / nominated boot drives, in which case you should be able to search for available disks devices and choose which one to boot from (see this "Ask Ubuntu" posting for example).
Key commands for EFI Shell:
- devices - to see available (and recognised) devices
- load - to load a file system driver
- mount - to mount device / directory
- ls - to see directory contents (helps you see if can find kernel to boot)
- if you mount the UEFI partition then you can see if: "grubx64.efi" is available and just invoke it directly or just exit, if root "/" is mounted then find kernel from ("/boot/vmlinux" for default via symlink) and invoke kernel directly.
If you can see your Linux root partition then you can boot directly from this by selecting kernel and bypass UEFI step. In this scenarios if you manage to boot linux then you should then do a reinstall of your EFI partition (as per "Converting Ubuntu from bios to UEFI"):
--- Using Live CD boot your machine, boot using "Try Ubuntu" option
--- Depending on your machines disk type, the disk could be on any of:
--- sdX - sata
--- vdX - virtio
---
-- Now ensure you have grub-efi installed on your Live environment
--
$ sudo apt install grub-efi
---
--- Create directories to mount disks and mount them
---
$ cd /media
$ sudo mkdir ROOT
$ sudo mkdir EFI
$ sudo mount /dev/vda2 /media/ROOT
$ sudo mount /dev/vda1 /media/EFI
---
--- Now install grub
---
$ sudo grub-install --target=x86_64-efi /dev/vda --efi-directory=/media/EFI --boot-directory=/media/ROOT/boot
Installing for x86_64-efi platform
Installation finished. No error reported.
---
--- cd into ROOT/etc and edit fstab to include mounting of efi
--- Here is sample after editing (see /boot/efi entry)
---
$ cd /media/ROOT/etc
$ cat fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
#
UUID=83199e8d-6d80-4db9-8dc1-8e7eed326d4e / ext4 errors=remount-ro 0 1
UUID=214A-5446 /boot/efi vfat defaults 0 0
UUID=4006ff1d-8a08-4dac-8a18-c3a8a3d542a3 none swap sw 0 0
---
--- Now reboot from hd
---
GRUB Failure
With UEFI a GRUB failure could be that the UEFI based GRUB "shim" cannot find the reference boot disk or that it found the boot disk but cannot resolve the boot directory provided directieves. With Ubuntu ther are two configuration file locations:
- /EFI/ubuntu/grub/grub.cfg - on the UEFI boot partition (FAT16/FAT32 formatted partition). Just a simple configuration which points to main GRUB configuration
- /boot/grub/grub.cfg - on root "/" disk partition of your Ubuntu boot disk. This has the more complete GRUB boot menu definitions
Here is example of GRUB boot failure and shell:

If you get to here then you need to use grub to find bootable kernel. GRUB is actually more work that EFI and sometimes it is just easier to do a GRUB re-install rather than muching around with it.
Key commands are:
- ls -look at directory contents (grub use disk names (hdX,partX))
- set root - define which disk/partition to boot from
- insmod - insert (load) grub module
- linux - load linux kernel
- initrd - load ram disk driver
- boot - boot linux
There are many example online, but before doing repair make sure you are using UEFI or BIOS specific instructions. See above for UEFI case.
Linux Kernel Load Failure
Kernel load failure can occur due to the kernel, initrd (initialise ramdisk) and modules libraries not being in sync.
In disk failure scenarios outline below it is possible that the grub install menu might be out of sync with actual software, resulting in failure, as "/lib" is symlink pointer to "/usr/lib".
The result was that while avoiding need for re-install there are still some "adjustments" that need to be finished to bring things back to "normal".
Load Failure - /lib/modules version out of sync with kernel
If you you did a "/usr" rebuild using new install on seperate disk and the cloned this over to "crashed" machine, then there is a chance your kernel (in "/usr/boot") is out of sync with "/lib/modules" as "/lib" is symlink to "/usr/lib".
To work around this you need to copy the same version kernel files over to your crashed machines root "/" directory (it is easy to bring kernel up to sync with modules as the kernel only consist of a few files. For example:
- vmlinuz-5.15.0-78-generic
- initrd.img-5.15.0-78-generic
- System.map-5.15.0-78-generic
- config-5.15.0-78-generic
Just copy these files into "/boot" and edit "/boot/grub/grub.cfg" to pickup the correct kernel version.
Linux Kernel Init Process Failure
Traditional System V Unix has concept of "runlevel" to defined different stage of boot process, with current linux this is now managed via systemctl, but basic concepts are still the same.
Computer boots but then hangs or crashes post boot. What is needed is to boot into "single" user code (or Recovery) mode.
This is achievable by using the GRUB boot selection menus, but this requires pressing keys at the right point in the boot process and then changing the boot selections.
A more repeatable approach is to:
- boot machine via USB and once boot check that file-systems are ok and
- mount machines "/" root filesystem (cd /tmp & mkdir ROOT & mount ...)
- Edit "/tmp/ROOT/boot/grub/grub.cfg" and change the default boot to what you need. The relevant section within file is:
...
...
...
menuentry 'Ubuntu' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-XXXX4924-XXXX-4XX8-8a55-8ca45558XXXX' {
recordfail
load_video
gfxmode $linux_gfx_mode
insmod gzio
if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi
insmod part_gpt
insmod ext2
set root='hd5,gpt2'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd5,gpt2 --hint-efi=hd5,gpt2 --hint-baremetal=ahci5,gpt2 XXXX4924-XXXX-4XX8-8a55-8ca455583434
else
search --no-floppy --fs-uuid --set=root XXXX4924-XXXX-4XX8-8a55-8ca45558XXXX
fi
linux /boot/vmlinuz-5.15.0-78-generic root=UUID=XXXX4924-XXXX-4XX8-8a55-8ca45558XXXX ro ipv6.disable=1 quiet splash iommu=1 intel_iommu=on ipv6.disable=1 $vt_handoff
# linux /boot/vmlinuz-5.15.0-78-generic root=UUID=XXXX4924-XXXX-4XX8-8a55-8ca45558XXXX ro ipv6.disable=1 single iommu=1 intel_iommu=on ipv6.disable=1 $vt_handoff
initrd /boot/initrd.img-5.15.0-78-generic
}
...
...
...The key line is: "linux /boot/vmlinuz-5.15.0-78-generic root=UUID=XXXX4924-XXXX-4XX8-8a55-8ca45558XXXX ro ipv6.disable=1 quiet splash iommu=1 intel_iommu=on ipv6.disable=1" which is the kernel boot and parameters line. For diagnostic verbose boot remove "quiet splan" and add "single" to boot into single user mode:
...
...
...
linux /boot/vmlinuz-5.15.0-78-generic root=UUID=XXXX4924-XXXX-4XX8-8a55-8ca45558XXXX ro ipv6.disable=1 single iommu=1 intel_iommu=on ipv6.disable=1 $vt_handoff
...
...
...
# NOTE: This example is from machine with Intel CPU (not AMD)
# and so has "intel_iommu=on" to allow PCI passthrough
#NOTE #1: As the machine has boot issue you will need to boot via USB and edit file and then do diagnostic boot
NOTE #2: You cannot achieve this by editing "/etc/default/grub" is this file provide input into the menu rebuild step ("sudo update-grub") and requires a bootable machine to execute.
NOTE #3: Booting into single user mode will put the machine at "runlevel 1"
Once booted to "runlevel 1" you can use logs to help with diagnosis and also boot step up to higher levels incrementally ("init" command) to help determine which part of boot process the failure is in (ie during network start or GUI startup etc).
Example - Fails to get to Runlevel 3 due to permissions problem
Recently I found that doing this on crashed Ubuntu Linux install problem was going to runlevel 3 (multi-user + networking). Looking at logs it was not apparent what problems was.
So going back to runlevel 2 I found I could log in to root about (require root account to be enabled) but could not log into via user account. At login it would sucessfully authenticate, but then dump me back at login prompt and as console message was lost, I could not see what reported problem was.
This is typically an case where there is issue accessing shell. So logging into root and doing "su - USER" was as getting "/bin/bash: permission denied" message.
The problem was that a failed "MegaRAID Storage Manager" installation had resulting in all the critical "/", "/usr", "/etc" directory permissions lossing group & all "rx" permissions being removed. So resolution was to reset these. To do this needed to first find out what the correct permission should be. This done by going to know good Ubuntu 22.04 install and getting permission of all directories and subdirectories via "stat" and then using this to generate "chmod" scripts that could be applied to crashed machine:
---
--- 1. Get correct permissions from known good machine
---
# find /bin /etc /usr /snap -type d -exec stat --format "chmod %a %n" {} \; > chmod-to-dirs-01.sh
---
--- 2. Transfer this list to crashed machine
--- as it can only get to runlevel 2 (no network) this is via
--- USB boot and then mount disk to save onto local disk
--- get via sftp
---
--- 3. On "bad" machine login to root and source the file
--- also ensuring that root is ok as well
---
# chmod 775 /
# source chmod-to-dirs-01.txt
# rebootNOTE #4: I use "source" as it likely that there will be variation between good and bad machines and you just want to continue going if it cannot find the directory
NOTE #5: If problem extends to files as well then do the same but with find for standard files "find ... -type f ..."
User Process Failure
Example is "MegaRaid Storage Manager" install failure. This resulted in changinng permission on all system directories so that they did not have general group/all as "read & execute" (rx).
The fix to this is covered above in "Example - Fails to get to Runlevel 3 due to permissions problem".
Other things that are likely to be required when server crashes, include:
- Stop boot to UI - if your machine is hosed then you will need to boot of USB and change the grub boot configuration
- Stop libvirt/QEMU virtual machines from running
Stop UI from loading (once machine is bootable again ...)
If you cannot log in or fully boot then being able to stop GUI via systemctl is not very helpful. In these cases you will have to boot from USB and then edit
"/usr/boot/grub/grub.cfg" (as per "Linux Kernel Init Process Failure")
If you can get to runlevel 3 then system control is useful to stop machin from booting up to GUI:
---
--- 1. Set boot to target multi-user (runlevel 3)
---
# sudo systemctl set-default multi-user.target
---
--- 2. Set boot target to GUI (runlevel 5)
---
# sudo systemctl set-default graphical.target
---Stop machine from auto-starting VMs via libvirt/QEMU
If you are using your server to hot VMs via libvirt/QEMU then you will not want to have it auto-starting VMS on startup (this will happen at runlevel 3). There are three typical things that need to be done:
- Stop all runnings VMs
- Stop VMs from auto-starting (and be able to restore the auto-start once all is in order)
- Disable virtlib daemon completely
Example commands which do echo so you can test them before using them:
---
--- 1. Stop all running vms
--- - just remove the echo..
---
# for domain in `virsh list --state-running | grep 'running' | awk '{print $2}'` ; do echo "virsh shutdown ${domain}" ; done
---
---
--- 2a. Stop VMs from auto-starting and save record for latter
---
# for domain in `virsh list --autostart --all | grep 'stopped\|running' | awk '{print $2}' | tee save-for-later.txt` ; do echo "virsh autostart --disable ${domain}" ; done
---
---
--- 2b. Reestablish auto-start disable in 2a
---
# for domain in `cat save-for-later.txt`; do echo "virsh autostart --enable ${domain}" ; done
---
---
--- 3. Disable libvirtd
--- First stop it and then disable it
---
# systemctl stop libvirtd
# systemctl disable libvirtd
---
--- to re-enable just use "enable"
---
Storage Failure & Recovery
The simple mantra - back up and back up. The reality for most small environments is that, things need to be done based on priority:
- home "/home & other directories - Very important (apply simple mantra & use redundancy)
- root "/" - important as this is needed to boot and has your configuration information (mostly in "/etc") (use redundancy)
- user "/usr" - less important as this mostly the same for any installation and can be regenerated (via "/" root & "/var" var) (use redundancy but know you to rebuild)
- var "/var" - important as this has cache of many files and logs etc (use redundancy)
- tmp "/tmp" - not important as it just tempory data
So applying above machine get partitioned so it has five seperate file system (and associated disks/raids), so single failure is non-impacting and double failure (within same file sytem) is contained to single file system.
/usr - gone
If you loose your "/usr" mounted file system then conventional approach is to do a complete Ubuntu reinstall which "re-uses" (unchanged) your "/home" mounted file-system. The downside if this approach is that you will have redo any apt and other installs to bring the system back up to prior configuration.
This is not really needed as the "/usr" mostly contains deployed software (OS and others) and so does does not contain any specific installation confguration. So alternate approach is to:
- Fix / replace your crashed disk/raid cluster (for "/usr" I am now using RAID-1 (mirror) with hot standby as this means you can have two failures and still be ok, while if you have RAID-5 you need to have 3 disks and if you get two failures your data is lost. This works as "/usr" does not need much disk space (1TB is more than sufficient).
- Create new "clean" Ubuntu install of the same version as "crashed" machine (using removable or spare disk).
- Using "gparted" clone the newly installed "/usr" file system over to replacement disk/raid and give copy new UUID.
- Mount and edit crashed machine's root "/" and edit "/etc/fstab" to use UUID of cloned "/usr" file-system (use gparted to get partition UUID details)
- This should allow you to boot into "single" level on crashed machine
- Use "apt list --installed" to get list of all previously installed software and save this as a big long list
- Use "apt install --reinstall" to reinstall all the software you previously installed, using the long list from (6). This works pretty well and if you use the "long" method then it will only install each package once. The current apt install process also ensure that you prior configuration is maintained
Here are details:
---
---
--- 0. Go into runlevel 3 (assuming you have started in single user mode)
---
# sudo su
# init 3
---
--- 1. Get list of installed packages as long list
---
# sudo apt list --installed | grep -P '.*(?=/)' -o | awk '{print $1}' | awk '$1=$1' ORS=' ' > <APT_LIST.TXT>
---
--- 2. reinstall packages..
---
# apt install --reinstall $(cat <APT_LIST.TXT>)
# reboot
NOTE 6: You need to be at runlevel 3 so you can get packages from network
NOTE 7: Doing apt as long command line (not individual packages) ensures all the dependent packages only get reinstalled once
I have used this and it worked for Ubuntu 22.04, based on this StackExchange post. You could piple from Step 1 -> Step 2, but you might want to first look at command list to check it first ;-)
NOTE 8: For non apt installed software, you will have to either recall and reinstall this or use a convention of putting all installed sofware in a known location to allow reinstall. Be mindful that reinstallation can cause other failures (like the MegaRaid Storage Manager case documented above).
Links and References:
runlevel - the concept of system "runlevel" was introduced in UNIX System V. It defines a set of level that the system can transition through as it boots up, from: off (0) -> single user (1) -> multi-user (2) -> multi-user with networking (3) -> full (3 + GUI) (5) -> reboot (6). This is helpful when doing diagnosis as you can halt the initalisation process at a defined level to help with problem diagnosis and resolution.
UEFI Shell Commands - see Chapter 5 Shell Commands from UEFI specification
Ubuntu UEFI Booting - more information that you are likely to need to just recover from a crash
GRUB Commands - grub is grubby
Reinstall all apt packages & dependencies - this stack exchange has required information on this process
Picture from: "The crashes that changed Formula 1" (selected as no-one died)